
序論:なぜ「低Ping」という神話がトレーダーを誤解させるのか
金融取引、特にアルゴリズム取引の世界において、「速度」は絶対的な競争優位性である。この文脈で、多くのトレーダーやシステム管理者が絶対的な指標として盲信しているのが「Ping値」である。一般的なForex VPSプロバイダーは、こぞって「超低遅延」や「低Ping」を最大のセールスポイントとして掲げ、ブローカーサーバーへの近接性が取引パフォーマンスを決定づける唯一の要因であるかのようなマーケティングを展開している 1。
この業界の言説は、トレーダーの意識に、ICMPエコー要求/応答時間、すなわち「Ping値」という単一の、そして容易に理解できる数値を、パフォーマンスの究極的なベンチマークとして刷り込んできた。しかし、この単純化は危険な誤解を招く。本稿の核心的命題は、Ping値は「虚栄の指標(Vanity Metric)」に過ぎない、という点にある。
Ping値はネットワークの往復時間(Round-Trip Time)の一部を反映するに過ぎず、取引システム全体のソフトウェアおよびハードウェアスタック内に潜む、より複雑で、しばしば遥かに重大なボトルネックを完全に無視しているからである。
真の約定速度最適化は、市場の価格情報がトレーダーのシステムに到達し、アルゴリズムが判断を下し、注文が取引サーバーに送り返されるまでの一連のプロセス、すなわち「Tick-to-Trade」ライフサイクル全体を包括的に分析することによってのみ達成される 4。
本稿では、このライフサイクルを解剖し、遅延の二つの根源的な形態—ネットワークレイテンシーと計算レイテンシー—を明確に区別する 5。そして、Ping値という一面的な指標への固執が、いかにして不適切なインフラ投資と、誤った安心感へと導くかを論証する。
約定遅延の解剖学:ネットワークレイテンシーと計算レイテンシー
約定遅延を正確に理解するためには、まず遅延をその構成要素に分解する必要がある。全ての遅延は、本質的に「ネットワークレイテンシー」と「計算レイテンシー」という二つのカテゴリに分類できる。
ネットワークレイテンシー (Network Latency)
ネットワークレイテンシーとは、データが物理的な媒体(光ファイバー、銅線など)を通じて、ある地点から別の地点へ移動するために要する時間である 6。これは「輸送中の時間(Time in Transit)」と定義できる。この遅延の大きさは、主に以下の要因によって決定される。
- 物理的距離: トレーダーのサーバーとブローカーの取引サーバー間の物理的な距離。光速という普遍的な物理法則の制約を受けるため、距離は最も根本的な要因となる。
- ネットワーク品質: 経路上に存在するスイッチ、ルーターなどのネットワーク機器の性能や、ネットワーク経路の混雑度。経由する機器(ホップ数)が多ければ多いほど、遅延は増加する 8。
一般的に「Ping値」が測定しようと試みているのは、このネットワークレイテンシーである。
計算レイテンシー (Compute Latency)
計算レイテンシーとは、コンピュータシステムがデータを受信してから、それを処理し、応答を生成するまでに要する時間である 5。これは「処理中の時間(Time in Processing)」と定義される。MT5の文脈においては、以下の処理時間が含まれる。
- データ受信処理: ネットワークカードが受信した価格データ(ティック)をOSが処理し、MT5アプリケーションに渡すまでの時間。
- EAのロジック実行: MT5がティックをExpert Advisor (EA)に渡し、EAがその内部ロジック(テクニカル指標の計算、統計モデルの評価、機械学習による予測など)を実行し、売買判断を下すまでの時間。
- 注文生成処理: EAが下した判断に基づき、MT5が取引サーバーへの注文データを生成し、OSを通じてネットワークカードに送信するまでの時間。
Tick-to-Tradeライフサイクルの分解
高頻度取引(HFT)の世界で用いられる分析フレームワークをMT5に応用すると、約定遅延の全体像は以下のように分解できる 4。
- 市場イベント → トレーダーサーバー (ネットワークレイテンシー): ブローカーの取引サーバーで価格変動が発生し、その情報がネットワークを介してトレーダーのサーバーに到達するまでの時間。
- データ処理と意思決定 (計算レイテンシー): トレーダーのサーバーがティックデータを受信し、EAが取引アルゴリズムを実行して注文を出すべきか否かを決定するまでの時間。これは最も見過ごされがちな遅延要素である。
- 注文送信 → ブローカーサーバー (ネットワークレイテンシー): 生成された注文データが、トレーダーのサーバーからネットワークを介してブローカーの取引サーバーに到達するまでの時間。
総約定遅延は、これら3つのステージの時間の総和である。
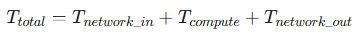
という単純な数式で表される。この事実が示唆するのは、遅延は連鎖しており、その鎖全体の強度は最も弱い環によって決定される、ということである。例えば、ネットワークレイテンシーを極限まで最適化し1ミリ秒を達成したとしても、EAの計算レイテンシーが100ミリ秒を要する場合、その1ミリ秒のネットワークは事実上無意味である。真の最適化とは、単に「遅延を減らす」ことではなく、この連鎖の中で最大のボトルネックとなっている要素を特定し、解消することから始めなければならない。
MT5アーキテクチャの罠:シングルスレッド実行という看過されがちな現実
MT5プラットフォームの技術的優位性は広く知られている。32ビット・シングルスレッドアプリケーションであった旧世代のMT4とは異なり、MT5は64ビット・マルチスレッドアプリケーションとして設計されており、特にバックテストの速度や複数銘柄の同時処理能力において、MT4を遥かに凌駕する 9。この事実は、多くの開発者やトレーダーに「MT5は最新のマルチコアCPUの性能を最大限に引き出せる」という印象を与えている。
しかし、ここに重大な落とし穴が存在する。MT5ターミナル自体はマルチスレッドで動作する一方で、MQL5の実行環境は、個々のExpert Advisor (EA)に対して厳密に1つのスレッドしか割り当てないのである 11。これはMQL5の公式ドキュメントに明記されている、議論の余地のない技術的仕様である。
このシングルスレッド実行モデルが持つ意味は極めて大きい。どれほど複雑なロジックを持つEAであっても、その中核的な計算処理は、常に単一のCPUコアしか利用できない 11。もちろん、MT5ターミナルは複数のEAを異なるチャート上で実行し、OSがそれらを別々のCPUコアに割り当てることで並列処理を行うことは可能である 13。しかし、単一のEA内部のロジック(例えば、OnTick()関数内で実行される一連の計算)は、逐次的に、ただ1つのCPUコア上で処理される。
このアーキテクチャ上の制約は、「EAの高速化」という課題に対するハードウェア選定の常識を根底から覆す。多くのシステム管理者が直感的に信じている「より多くのコア数 = より高いパフォーマンス」という等式は、単一のEAの処理速度向上という文脈においては、全く成り立たない。8コア、16コア、あるいは32コアといったハイエンドなCPUを搭載したサーバーを導入しても、単一の計算集約型EAのパフォーマンスは全く向上しない。なぜなら、そのEAが利用できるのは8つや16あるコアのうちのたった1つであり、残りのコアはそのEAの計算中はアイドル状態のままだからである。ボトルネックは利用可能な処理レーンの数ではなく、EAが走行を強制される単一レーンの速度なのである。
したがって、計算集約型EAのパフォーマンスを決定づける最も重要なCPUのスペックは、コア数ではなく、シングルスレッド性能となる。そして、シングルスレッド性能に最も強く相関するのは、CPUのクロック周波数 (GHz)と、クロックサイクルあたりの命令実行数(IPC)で決まるアーキテクチャの世代である 14。この看過されがちな技術的現実は、インフラ設計における誤った投資判断を防ぐための、極めて重要な鍵となる。
戦略の診断:あなたのEAは「ネットワーク集約型」か「計算集約型」か
前述の技術的洞察を実践的なインフラ設計に繋げるためには、まず自らのトレーディング戦略がどのタイプのボトルネックに直面しやすいかを診断する必要がある。全てのEAは、そのリソース消費の特性に基づき、大きく二つのアーキタイプに分類することができる。
アーキタイプ1:ネットワーク集約型戦略 (Network-Intensive)
このタイプの戦略は、競争優位性の源泉が、ほぼ完全に注文伝達と市場データ受信の速度に依存する。アルゴリズムのロジック自体は比較的単純であり、その実行時間はマイクロ秒から数ミリ秒程度で完了する。
- 具体例:
- レイテンシーアービトラージ: 異なるブローカー間のわずかな価格差を狙う戦略。
- 高頻度マーケットメイキング: 常に買値と売値を提示し、スプレッドから利益を得る戦略。
- ニューススキャルピング: 経済指標発表などのイベント発生直後の瞬間的な値動きを狙う単純なロジックのEA 8。
- 主要ボトルネック: ネットワークレイテンシー。ここでの目標は、競合他社よりも速く取引サーバーに到達する「レース」に勝利することである。
アーキタイプ2:計算集約型戦略 (Compute-Intensive)
このタイプの戦略は、競争優位性の源泉が、分析モデルの複雑性と高度さにある。計算処理に要する時間が、総約定遅延の中で無視できない、あるいは支配的な要素となる。
- 具体例:
- 多数のテクニカル指標を複数の時間足にわたって計算するEA。
- 統計的裁定取引(ペアトレーディングなど)のように、複雑な統計モデルを用いる戦略。
- オーダーフロー分析のように、膨大なティックデータを処理して市場の需給を判断する戦略 18。
- 予測のために機械学習(ML)モデルを組み込んだEA。
- 主要ボトルネック: 計算レイテンシー。ここでの目標は、より質の高い取引シグナルを生成するための複雑な分析を、より速く完了させることである。
この診断から導かれる結論は、「万人にとって最適なトレーディングサーバー」というものは存在しない、ということである。ネットワーク集約型戦略に最適なインフラと、計算集約型戦略に最適なインフラは、その構成要素と投資の優先順位が根本的に異なる。汎用的なソリューションは、定義上、どちらのタイプの戦略に対しても準最適(sub-optimal)な結果しか もたらさない。ハードウェアを処方する前に戦略を診断するというプロセスこそが、真のパフォーマンスエンジニアリングの第一歩なのである 19。
ハードウェアの処方箋:戦略に基づいたインフラ設計
戦略の診断が完了すれば、次はその特性に合わせて最適化されたインフラを設計する段階に入る。以下に、各アーキタイプに対する具体的なハードウェアの処方箋を示す。
計算集約型戦略への処方箋
この戦略のボトルネックはCPUとストレージI/Oにあるため、インフラ投資はサーバー内部のコンポーネントに集中させるべきである。
- CPU: 絶対的な最優先事項は、最高クラスのシングルスレッド性能である。これは、コア数ではなく、CPUの最大ブーストクロック周波数 (GHz)と最新のアーキテクチャ(高いIPC)に基づいて選定することを意味する 14。単一のEAを実行する場合、3.5 GHzの8コアCPUよりも、5.0 GHzの4コアCPUの方が圧倒的に高いパフォーマンスを発揮する。
- ストレージ: NVMe (Non-Volatile Memory Express) SSDは、もはや選択肢ではなく必須要件である。その理由は、従来のSATA接続SSDと比較して、レイテンシーが劇的に低い点にある。SATA SSDのレイテンシーが約100-200マイクロ秒であるのに対し、NVMe SSDは約20-30マイクロ秒と、桁違いに高速である 20。大量のヒストリカルデータを読み込んだり、機械学習モデルのファイルをディスクからロードしたりするなど、ディスクI/Oが頻繁に発生するEAにとって、このマイクロ秒単位のI/O待ち時間の差が、計算レイテンシー全体を大幅に削減する上で決定的な役割を果たす 21。
ネットワーク集約型戦略への処方箋
この戦略のボトルネックはサーバー外部の接続性にあるため、インフラ投資は物理的なロケーションとネットワークに集中させるべきである。
- ロケーション(コロケーション): 最も重要な要素は、ブローカーの取引サーバーへの物理的な近接性である。これを実現する唯一の方法が、Equinix LD4(ロンドン)やNY4(ニューヨーク)といった主要な金融データセンター内でのコロケーションである 2。一般的な「ロンドンVPS」は、データセンターから数キロ離れた場所にあり、公衆インターネット網を経由して接続される可能性がある。一方で、コロケーションされたサーバーは、ブローカーのサーバーラックからわずか数メートルの距離に設置され、クロス・コネクトと呼ばれる専用の光ファイバーケーブルで直接接続することが可能である 23。これにより、ネットワークレイテンシーを物理的な限界(場合によっては1桁マイクロ秒)まで削減できる 7。
- ハードウェア: ハードウェアの要求仕様は、計算集約型戦略ほど厳しくはない。計算負荷が低いため、堅実なベースライン性能を持つCPUとNVMe SSDで十分である。投資の優先順位は、サーバー内部のコンポーネントから、コロケーション施設の利用料やクロス・コネクトの接続費用へとシフトする。
これらの推奨事項を以下の表に要約する。
| 特性 | ネットワーク集約型戦略 | 計算集約型戦略 |
| 主要ボトルネック | ネットワーク伝送遅延 | CPU/I/O処理時間 |
| 最優先インフラ | 金融DCでのコロケーション | 高クロック周波数CPU |
| CPU選定 | 良好なベースライン性能 | 最高クラスのシングルスレッド性能 |
| ストレージ | NVMe SSD (推奨) | NVMe SSD (必須) |
| ロケーション | ブローカーサーバーと同一DC (LD4, NY4等) | ブローカーサーバーに近いDC |
この表は、インフラ設計が画一的なものではなく、戦略の特性に応じて最適化されるべき動的なプロセスであることを明確に示している。
結論:汎用VPSの限界と、真の競争優位性を築くために
本稿では、まず一般的なForex VPSプロバイダーが喧伝する「低Ping」という神話に異議を唱えることから始めた 1。次に、約定遅延をネットワークと計算という二つの要素に分解し 5、MQL5 EAが本質的にシングルスレッドで実行されるという、見過ごされがちなアーキテクチャ上の制約を明らかにした 11。最終的に、トレーディング戦略を診断し、その特性に合わせたインフラを処方するための具体的なフレームワークを提示した。
この分析から導き出される必然的な結論は、市販の標準的なVPSは、本質的に妥協の産物であるということである。それは、外科手術用のメスを必要とするタスクに対して、鈍器を振るうようなものである。ネットワーク集約型戦略にとっては、真のコロケーションとクロス・コネクト機能が欠けている。計算集約型戦略にとっては、低いクロック周波数のCPUや低速なストレージといった、準最適なハードウェアを提供されることが多い。
今日の競争が激化する市場において、持続可能な取引上の優位性(アルファ)は、もはや優れた戦略単体では生み出せない。それは、優れた戦略と、その戦略を完璧に実行するために最適化されたインフラストラクチャ・スタックとの共生関係の産物なのである。
トレーディング戦略の固有の計算特性(Computational Fingerprint)を診断し、それに合致するハードウェアとネットワークのソリューションをオーダーメイドで設計する—このような高度なシステムアーキテクチャの構築は、汎用的なホスティング企業の領域ではなく、専門的なFinTechエンジニアリング・パートナーの領域である。真の競争優位性を追求するトレーダーや企業にとって、自らの戦略に最適化されたインフラへの投資は、もはや贅沢ではなく、不可欠な要件となっているのである 19。
引用
- What is a Forex VPS? Boost Speed & Stability in 2025 – Bluehost, https://www.bluehost.com/blog/what-is-forex-vps/
- Best Cheap Forex VPS 2025: Low-Latency, Reliable & Budget Plans Compared, https://myforexvps.com/best-cheap-forex-vps-2025-low-latency-reliable-budget-plans-compared/
- Forex VPS hosting | Trade faster and more securely – Hostinger, https://www.hostinger.com/vps/forex-hosting
- How is latency analyzed and eliminated in high-frequency trading? – Pico, https://www.pico.net/kb/how-is-latency-analyzed-and-eliminated-in-high-frequency-trading/
- Network Latency vs. Compute Latency – Interconnections – The …, https://blog.equinix.com/blog/2024/03/27/network-latency-vs-compute-latency/
- Future Proofing Network Latency in Stock Trading – PacketLight Networks, https://www.packetlight.com/resources/articles/future-proofing-network-latency-in-stock-trading
- How to Achieve Ultra-Low Latency in Trading Infrastructure – BSO-Network, https://www.bso.co/all-insights/achieving-ultra-low-latency-in-trading-infrastructure
- Benefits of Low-Latency Networks For Prop Trading Firms – BSO-Network, https://www.bso.co/all-insights/benefits-of-low-latency-networks-for-prop-trading-firms
- MT4 vs MT5: Which Platform is Best for Your Trading Style? | Billions Club – For Traders, https://www.fortraders.com/blog/mt4-vs-mt5-which-platform-is-best-for-your-trading-style
- MetaTrader 4 vs MetaTrader 5: Which Platform Should You Use? – VPSForexTrader, https://www.vpsforextrader.com/blog/metatrader-4-vs-metatrader-5/
- Threads – Creating application programs – MQL5 Programming for …, https://www.mql5.com/en/book/applications/runtime/runtime_threads
- Parallel Calculations in MetaTrader 5 – MQL5 Articles, https://www.mql5.com/en/articles/197
- Once again, about multithreading – Hanging Man – General – MQL5 programming forum, https://www.mql5.com/en/forum/394900
- A few Thoughts about Single Thread Performance – Oracle Blogs, https://blogs.oracle.com/solaris/post/a-few-thoughts-about-single-thread-performance
- A Look Back at Single-Threaded CPU Performance – Preshing on Programming, https://preshing.com/20120208/a-look-back-at-single-threaded-cpu-performance/
- Low Latency Trading: What it is and How Does it Work? – ForexVPS, https://www.forexvps.net/resources/low-latency-trading/
- What is High-Frequency Trading? A Complete Beginner Guide – mastertrust, https://www.mastertrust.co.in/blog/what-is-high-frequency-trading
- Millisecond Frequency Trading – Quantra by QuantInsti, https://quantra.quantinsti.com/glossary/Millisecond-Frequency-Trading
- AI MQL
- NVMe Latency – simplyblock, https://www.simplyblock.io/glossary/nvme-latency/
- SSD vs. NVMe: What’s the difference? – IBM, https://www.ibm.com/think/topics/ssd-vs-nvme
- Understanding the Difference Between NVMe and SSD: A Simple Guide – Kamatera, https://www.kamatera.com/blog/nvme-vs-ssd-a-simple-guide/
- LD4 – Equinix, https://www.equinix.com/data-centers/europe-colocation/united-kingdom-colocation/london-data-centers/ld4