
序論:バックテストという名の「セイレーンの歌」
クオンツ金融の世界において、バックテストは長らく投資戦略の有効性を測るための黄金律と見なされてきた。しかし、洗練された研究者や開発者の間では、その結果がいかに脆く、誤解を招きやすいものであるかが広く認識されている。魅力的なエクイティカーブを描き出すバックテストは、研究者を誤った結論へと誘う「セイレーンの歌」に他ならない。本稿は、クオンツ金融界に蔓延する「バックテスト中心の研究」という方法論的誤謬を厳しく批判し、それに代わる科学的厳密性に基づいた新たなパラダイムを提示するものである。
多くの金融機械学習プロジェクトが失敗に終わる根本的な原因は、このバックテストへの過度な依存にある 1。これは単なる技術的なミスではなく、研究プロセスそのものに深く根差した構造的な問題である。この分野の第一人者であるMarcos Lopez de Prado氏は、この慣行に対して極めて厳しい警告を発している。「研究とバックテストは、飲酒運転のようなものだ。バックテストの影響下で研究をしてはならない」1。この警句は、バックテストがもたらすバイアスがいかに研究者の判断を歪め、客観性を失わせるかを的確に表現している。
この問題の核心には、統計学で「セレクション・バイアス(選択バイアス)」または「データスヌーピング」として知られる現象が存在する 1。これは、同じデータセットに対して多数の仮説(戦略)を試行する過程で、本来は偶然の産物である良好な結果を、あたかも真の市場の非効率性を捉えたかのように誤認してしまうことである。驚くべきことに、権威ある学術論文でさえ、この種の欠陥を持つバックテストの結果で溢れているという事実が指摘されており、これは業界全体が直面する深刻な課題であることを示唆している 1。
このリスクは定量的に示すことが可能である。標準的な統計的有意水準である5%(すなわち、20回に1回の割合で偶然に有意な結果が生じる)の下では、約20回の試行を行うだけで、統計的に有意に見える偽の投資戦略を発見してしまう可能性が非常に高くなる 7。これは、バックテストの繰り返しが、統計的偶然を必然的な「発見」へと変貌させてしまうプロセスに他ならない。
したがって、本稿における第一の主張は明確である。バックテストは研究ツールではない。それは、研究が完了した後に、ベットサイジング、取引コストへの耐性、あるいは特定のシナリオ下での挙動などを検証するための、限定的な目的で用いられるべき「サニティ・チェック」に過ぎないのである 3。真に頑健な投資戦略の研究開発は、バックテストのパフォーマンスから独立した、より科学的で再現性の高い方法論に基づかなければならない。その方法論こそが、「特徴量の重要性分析」である 5。このパラダイムシフトは、単なる技術的な改善提案ではなく、クオンツ金融における「発見」の定義そのものを問い直す、知的誠実性への回帰を促すものである。
第一部:市場の「隠れた文法」を解読する – 市場レジームの動態
バックテストが過去のパフォーマンスを将来にわたって保証できない根本的な理由は、金融市場が持つ「非定常性」という本質的な特性にある。市場は、単一の統計的性質を持つ静的な連続体ではない。むしろ、それぞれが異なるルールや「文法」(統計的特性)を持つ複数の「市場レジーム」が、不連続かつ予測困難に遷移していく動的なシステムなのである。この構造を理解することなくして、頑健な予測モデルを構築することは不可能である。
1.1 金融時系列の非定常性という現実
金融時系列データは、その平均、分散、自己相関といった統計的特性が時間と共に変化する「非定常性」を本質的に有している 9。これは、機械学習モデルが過去のデータから学習したパターンが、将来も同様に機能するという基本的な仮定を根底から覆す。非定常性の典型的な現れ方としては、持続的な価格の方向性を示す「トレンド」、特定の周期で繰り返される「季節性」、そして変動が静かな期間と荒い期間に集中する「ボラティリティ・クラスタリング」などが挙げられる 10。
伝統的な時系列分析手法、例えばARIMAモデルなどは、この非定常性に対処するために時系列の「差分」を取る操作を行う 11。これにより、系列は統計的に扱いやすい定常状態に変換される。しかし、このアプローチには重大な欠点が存在する。整数回の差分操作は、時系列データに含まれる長期的な相関やトレンドといった、予測において極めて重要な情報を過度に削ぎ落としてしまう「過剰差分」のリスクを伴うのである 9。結果として、ノイズは除去されるものの、シグナルまでもが失われ、モデルの予測能力が著しく低下する可能性がある。非定常性は単に除去すべき統計的な厄介事ではなく、市場の構造的変化を示す重要な情報源なのである。
1.2 市場レジームの定義と特性
市場レジームとは、市場の統計的特性(平均リターン、ボラティリティ、資産間の相関など)が急激に変化し、その変化した状態が一定期間持続する現象として定義される 12。このレジームの概念は、非定常性をより構造的に理解するための強力なフレームワークを提供する。市場は、単一の確率過程に従うのではなく、複数の異なる確率過程(レジーム)の間を遷移していると考えるのである。
これらのレジームは、単なる統計上の抽象的な区分ではない。多くの場合、それらは現実世界の具体的な出来事と密接に対応している。例えば、規制環境の変更、中央銀行による金融政策の転換(1979-1982年のボルカー・ショックなど)、景気後退期と拡大期のサイクル、あるいは2008年の世界金融危機や2020年のコロナショックといった大規模な地政学的・経済的イベントが、レジームシフトの引き金となることが知られている 12。
レジームは分析の目的に応じて様々な形で分類される。代表的なものには、「強気市場(ブル) vs 弱気市場(ベア)」、「高ボラティリティ vs 低ボラティリティ」、あるいは投資家のリスク許容度を反映した「リスクオン vs リスクオフ」といった分類が存在する 12。あるレジームで有効であった戦略が、別のレジームでは全く機能しない、あるいは壊滅的な損失をもたらすことは頻繁に起こり得る。これが、特定の期間のデータに過剰適合したバックテストが必然的に失敗する核心的な理由である。
1.3 レジーム変化を検出する技術
どのレジームがいつまで続くかを事前に知ることはできないため、市場レジームの特定は本質的に教師なし学習の問題として扱われる 16。観測された時系列データから、その背後にある「隠れた状態」を推測する必要がある。
この目的のために最も広く用いられる代表的な手法が、隠れマルコフモデル(Hidden Markov Model, HMM)である 13。HMMは、観測可能なデータ(日次リターンやボラティリティ指数など)の背後に、直接観測することはできないが、システムの状態を決定づける離散的な「隠れた状態」(=市場レジーム)が存在すると仮定する。そして、これらの隠れた状態がマルコフ過程(現在の状態が直前の状態のみに依存して確率的に遷移するプロセス)に従うとモデル化する 12。HMMは、各レジームが持つ固有の統計的特性(例えば、高ボラティリティ・マイナスリターンの「暴落レジーム」や、低ボラティリティ・プラスリターンの「安定成長レジーム」など)をデータから学習し、特定の時点において市場がどのレジームに属しているかの確率を推定することができる 14。
他のアプローチとして、k-means法などのクラスタリングアルゴリズムも存在する 18。しかし、金融データ特有の性質、すなわち正規分布から大きく逸脱したファットテール(極端な事象の発生確率が高い)や自己相関を考慮しない、単純なユークリッド距離に基づくk-means法は、レジームを適切に分離できない可能性がある 20。金融データの分布形状そのものを捉えるために、分布間の距離(例えばワッサースタイン距離)をクラスタリングの指標として用いるなど、より洗練された手法が有効であることが示唆されている 18。これらの手法は、市場の非定常性を構造的なレジーム変化として捉え、より現実に即した市場分析を可能にするための不可欠なツールである。
第二部:未来を予測するための「原材料」- レジーム変化に頑健な特徴量エンジニアリング
市場がレジーム変化という構造的な非定常性を抱えている以上、真に頑健な予測モデルを構築するための解決策は、モデルのハイパーパラメータを調整するといった表面的な作業にあるのではない。それは、モデルに入力される「原材料」、すなわち「特徴量」そのものの質を根本的に高めることにある。レジームが変化してもその予測能力が劣化しにくい、普遍的な市場の動態を捉えた特徴量をいかにして生成するか。本セクションでは、この課題に対する二つの先進的なアプローチ、すなわち統計的特性を制御する「分数次差分」と、価格変動の根源的要因を捉える「マーケット・マイクロストラクチャー特徴量」について詳述する。
2.1 非定常性との闘い – 記憶を保持する分数次差分
第一部で論じたように、金融時系列の非定常性を解消するために従来から行われてきた整数次差分(例:価格の差分を取ってリターンを計算する)は、重大なジレンマを内包している。それは、統計的な安定性を得る代償として、価格時系列に内在する予測能力の源泉、すなわち「記憶(長期依存性)」を破壊してしまうことである 22。市場の過去の動きが未来に与える影響のパターンこそが予測の鍵であるが、過剰な差分操作はこの貴重な情報を完全に消し去ってしまう。
このジレンマを解決するためのエレガントな数学的解法として、Marcos Lopez de Prado氏が提唱する「分数次差分(Fractional Differentiation)」が注目されている 22。この手法の核心は、時系列を整数回(例えば$d=1$)ではなく、0から1の間の実数値$d$で差分を取ることにある。ADF検定などの統計的検定を用いながら、$d$の値を徐々に大きくしていくことで、時系列が必要な定常性を満たす「最小限の」差分を見つけ出すことが可能となる 22。
具体的には、分数次差分系列\tilde{X}tは、元の系列X_tを用いて以下のように計算される。
\tilde{X}t = \sum{k=0}^{\infty} w_k X{t-k}
ここで、重み$w_k$は次式で与えられる。
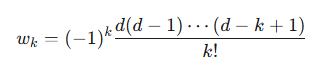
実用上は、計算負荷を考慮し、過去のデータ点を一定のウィンドウ幅に限定するFFD(Fixed-width window fracdiff)法が用いられる 22。
このアプローチにより生成された特徴量は、元の時系列が持っていた予測に有用な「記憶」を最大限保持しつつ、統計的に安定しているため、機械学習モデルの入力として理想的な特性を持つ。De Prado氏が指摘するように、「事実上すべての金融論文は整数次差分を適用することで定常性を回復しようと試みてきた。これは、ほとんどの研究が系列を過剰に差分し、標準的な計量経済学の仮定を満たすために必要以上の記憶を消し去ってきたことを意味する」22。分数次差分は、この長年の課題に対する強力な解決策を提供するものである。
2.2 価格変動のDNAを抽出する – マーケット・マイクロストラクチャー特徴量
移動平均やRSIといった、ローソク足チャートから計算される伝統的なテクニカル指標は、価格という「結果」のみを分析対象としている。しかし、価格変動の真の駆動要因は、その結果が生まれる「プロセス」の中に存在する。すなわち、無数の買い注文と売り注文がどのように相互作用し、取引が執行されるかというメカニズムそのものである。この市場の内部構造と取引執行プロセスを研究する分野が「マーケット・マイクロストラクチャー」であり、ここにこそレジーム変化に対してより頑健な、根源的なシグナルが眠っている 26。
マーケット・マイクロストラクチャー特徴量は、注文板(リミットオーダーブック)、約定データ(ティックデータ)、取引フローといった高解像度のデータから生成される 28。これらの特徴量は、投資家心理の集合体や、市場参加者間の需給の不均衡を直接的に反映するため、マクロ経済環境が変化してもその有効性が比較的維持されやすい 4。以下に代表的な特徴量を挙げる。
- オーダーフロー・インバランス (Order Flow Imbalance – OFI): 一定期間内に発生した、買いのマーケット注文(アスク価格で即時約定を求める注文)と売りのマーケット注文(ビッド価格で即時約定を求める注文)の不均衡を捉える指標である 32。買いのOFIが正に大きい場合、強い買い圧力が存在することを示唆し、短期的な価格上昇の先行指標となることが広く知られている。OFIは、市場の「積極性」を直接計測するものである。
- 板情報に基づく特徴量:
- 注文板の厚み (Market Depth): 現在の最良気配値から一定範囲内に存在するリミットオーダーの総量。厚みがある市場は流動性が高く、大きな注文でも価格への影響が少ないことを示す 29。
- ビッド・アスク・スプレッド: 最良買い気配値と最良売り気配値の差。スプレッドの拡大は、流動性の低下や不確実性の増大を示唆する 30。
- VAMP (Volume Adjusted Mid Price): 最良気配値だけでなく、その反対側の注文数量も加味して計算される加重平均価格。注文板の不均衡を価格に反映させる試みである 33。例えば、買い注文が厚く、売り注文が薄い場合、VAMPは単純な仲値よりも高くなる。
- 取引フローの毒性 (Trade Flow Toxicity): 市場には、公開情報のみを基に取引する「非情報トレーダー」と、独自の私的情報を持つ「情報トレーダー」が存在する。情報トレーダーの存在は、マーケットメーカーにとって逆選択のリスク(アドバース・セレクション)を高める。VPIN(Volume-Synchronized Probability of Informed Trading)などの指標は、取引フローがどの程度「有毒」(情報トレーダーによるもの)であるかを推定し、短期的な価格変動や流動性の枯渇を予測するために用いられる 35。
これらのマイクロストラクチャー特徴量は、価格という一次元の時系列データからは得られない、市場の多次元的な内部状態を明らかにする。これらは価格変動の「DNA」とも言うべき情報であり、これらを活用することで、市場レジームの変化というマクロな現象に対して、より頑健で安定した予測モデルの構築が可能となるのである。
第三部:幻想から科学へ – 偽発見を制御する厳密な特徴量評価
分数次差分やマーケット・マイクロストラクチャー分析によって、レジーム変化に頑健な特徴量の候補を生成したとしても、それで終わりではない。もし、これらの特徴量の有効性を評価するプロセスが、旧態依然としたバックテストに依存するならば、我々は再び「セレクション・バイアス」という名の偽発見の罠に陥るであろう。何百、何千もの候補特徴量の中から、過去のデータで最もパフォーマンスが良かったものを選択する行為は、まさにデータスヌーピングそのものである。本セクションでは、バックテストに代わる、科学的厳密性に基づいた特徴量評価のフレームワークを提示する。その核心は、評価の焦点をパフォーマンスから統計的有意性へと移し、多重比較の罠を回避するための知的誠実性を確保することにある。
3.1 特徴量重要度分析という新基準
評価パラダイムの転換は、Marcos Lopez de Prado氏が提唱する第一法則に集約される。「バックテストは研究ツールではない。特徴量重要度が研究ツールである」5。この宣言は、我々の探求の対象が「儲かる戦略」ではなく、「予測能力を持つ特徴量」でなければならないことを意味する。戦略のパフォーマンスは、予測能力のある特徴量から派生する結果に過ぎない。したがって、研究開発プロセスの中心に据えるべきは、バックテストの損益曲線ではなく、各特徴量が持つ真の予測能力を多角的に評価する「特徴量重要度分析」である。
主要な特徴量重要度分析手法には、それぞれ長所と短所があり、組み合わせて用いることが推奨される。
- MDI (Mean Decrease Impurity): ランダムフォレストなどのツリーベースのアンサンブルモデルに特有の手法である。モデルの学習過程(インサンプル)において、各特徴量が分岐点(ノード)でどれだけ不純度(Impurity)を減少させたかを平均することで重要度を算出する 5。計算が非常に高速である一方、インサンプル評価であるため過学習した特徴量を過大評価するリスクがある。また、互いに相関の高い(共線性のある)特徴量が存在する場合、その重要度が特定の特徴量に偏って分配される傾向がある 35。
- MDA (Mean Decrease Accuracy): モデルの種類に依存しない、より汎用性が高く信頼性の高いアウトオブサンプル評価手法である 5。まず、交差検証(Cross-Validation)を用いてモデルのベースラインとなる性能スコア(例:正解率やF1スコア)を測定する。次に、評価対象の一つの特徴量の値をランダムにシャッフル(順列置換)し、その特徴量が持つ情報を破壊する。この状態で再度モデルの性能を測定し、ベースラインからの性能低下の度合いをその特徴量の重要度とする。アウトオブサンプルで評価するため過学習に強く、信頼性が高いが、特徴量の数だけモデル評価を繰り返すため計算コストが非常に高い。
- SFI (Single Feature Importance): 各特徴量を「単独で」用いてモデルを学習させ、そのアウトオブサンプル性能を評価する手法である 5。このアプローチの最大の利点は、特徴量間の代用効果(Substitution Effects)を排除できることにある。代用効果とは、似たような情報を持つ複数の特徴量が存在する場合、モデルがそのうちの一つを主要な予測子として採用すると、他の特徴量の重要度が不当に低く評価されてしまう現象である。SFIは各特徴量を独立に評価するため、この問題を回避できる。一方で、特徴量間の相互作用(複数の特徴量が組み合わさって初めて生まれる予測力)を捉えることはできない。
これらの手法を組み合わせることで、ある特徴量が単独で予測能力を持つのか、他の特徴量との組み合わせで重要になるのか、あるいは単なる統計的な偶然や他の特徴量の代理に過ぎないのかを、多角的に評価することが可能となる。
3.2 多数の仮説検定がもたらす統計的罠
何百、何千もの候補特徴量の重要度を評価する行為は、統計学の世界では「多重比較問題」または「多重仮説検定問題」として知られる古典的な課題そのものである 35。我々は、「この特徴量は予測能力を持つか?」という仮説を、特徴量の数だけ同時に検定しているのである。
この状況下で、個々の検定において伝統的な有意水準(例えば$p < 0.05$)を単純に適用すると、深刻な問題が生じる。それは、全体として少なくとも一つの偽陽性(本来は無意味な特徴量を「重要」と誤って判断してしまうこと)を犯す確率、すなわち「ファミリーワイズエラー率(Family-Wise Error Rate, FWER)」が、検定数が増えるにつれて急激に増大することである 37。例えば、真に無意味な100個の特徴量を検定した場合、約99.4%の確率で少なくとも一つが「有意」であるという誤った結論に至ってしまう。
この問題を解決するための古典的な手法として、ボンフェローニ補正のようなFWER制御手法が存在する。これは、個々の検定に用いる有意水準を、元の有意水準を検定数で割った値(例:$0.05 / 1000$)に設定するという、非常に厳格なアプローチである 39。しかし、この方法はあまりに保守的すぎるため、偽陽性を抑える代償として、真に有用な特徴量を見逃すリスク(偽陰性)を著しく高めてしまう。特に、探索的な特徴量エンジニアリングのように、多数の候補の中から少数の有望なシグナルを発見しようとする場面には不向きである。
3.3 偽発見率(FDR)による知的誠実性の確保
FWERの厳格すぎる基準と、何もしないことによる偽発見の氾濫というジレンマを解決するために、より現代的で実用的なアプローチとして「偽発見率(False Discovery Rate, FDR)」の制御が提案されている 37。
FDRは、FWERとは異なるエラー率の概念を導入する。FWERが「少なくとも一つの偽発見も許さない」という確率を制御するのに対し、FDRは「『重要である』と判断された(発見された)特徴量全体のうち、実際に偽発見であるものの割合の期待値」を制御する 37。例えば、FDRを5%に制御するということは、「我々が『重要だ』と宣言した特徴量のリストには、平均して5%の偽物が含まれていることを許容する」という意味になる。このアプローチは、少数の偽発見を許容する代わりに、真の発見を逃さないためのより高い検出力(統計的パワー)を維持することを可能にする 39。
FDRを制御するための具体的な手順として最も広く知られているのが、Benjamini-Hochberg(BH)法である 37。この手順は非常にシンプルである。

FDRの概念とBH法のような手続きを特徴量評価プロセスに導入することは、単なる技術的な洗練に留まらない。それは、クオンツ研究に統計科学の厳密性をもたらし、再現性のない「発見」を体系的に排除するための知的誠実性を担保するものである。これにより、我々は自信を持って「この特徴量は、多数の候補の中から偶然選ばれたのではなく、統計的に制御されたプロセスを経て発見された、真に予測能力を持つシグナルである」と主張することが可能になるのである。
結論:AI MQLが提唱するクオンツ開発の新たなパラダイム
本稿で詳述してきた議論は、単一の技術的改善策の提示に留まるものではない。それは、バックテストという幻想から決別し、科学的厳密性と市場の構造的理解に基づいた、クオンツ開発の新たなパラダイムへの移行を提唱するものである。このパラダイムは、再現性が高く、市場の不確実性に対して真に頑健な投資戦略を構築するための、知的で体系的なフレームワークを提供する。
伝統的なクオンツ開発は、しばしば「アイデア → バックテスト → 過学習」という非生産的な悪循環に陥りがちであった。これに対し、我々が提唱する現代的なワークフローは、このサイクルを断ち切り、より持続可能なアルファ創出のプロセスを構築する。
表1:伝統的アプローチ vs. 現代的パラダイムの比較
| 側面 | 伝統的(欠陥のある)アプローチ | AI MQLが提唱する現代的パラダイム |
| 主要な研究ツール | バックテストのパフォーマンス | 特徴量重要度分析 |
| 非定常性への対処 | 整数次差分(記憶の喪失) | 分数次差分(記憶の保持) |
| シグナルの源泉 | 価格由来のテクニカル指標 | マーケット・マイクロストラクチャー特徴量 |
| 検証方法 | パフォーマンス指標(例:シャープレシオ) | 統計的有意性(FDR制御下のp値) |
| 主要なリスク | バックテストの過学習、偽発見 | モデルの誤特定(より管理可能なリスク) |
| 最終的な成果物 | 脆く、非頑健な戦略 | 頑健で、適応力のある戦略 |
この新たなパラダイムが示すワークフローは、以下の4つの連続したステップで要約される。
- 市場の構造的理解: あらゆる分析の出発点として、市場が静的ではなく、非定常性とレジーム構造を持つ動的なシステムであることを深く認識する。
- 頑健な特徴量生成: 価格という表層的な情報に留まらず、分数次差分を用いて時系列の統計的特性を制御し、マーケット・マイクロストラクチャー分析によって価格変動の根源的要因を捉えることで、レジーム変化に強い特徴量をエンジニアリングする。
- 厳密な科学的評価: バックテストの損益曲線に惑わされることなく、偽発見率(FDR)を制御した統計的フレームワークの下で、特徴量重要度分析を実行する。これにより、真に予測能力を持つ特徴量のみを科学的に特定する。
- モデル構築とリスク管理: 厳密に選別された特徴量を用いて初めて予測モデルを構築する。この最終段階において、バックテストはベットサイジングやコスト耐性の検証といった、限定的なサニティ・チェックの役割を果たす。
このアプローチは、単に優れた戦略を生み出す可能性を高めるだけではない。それは、なぜその戦略が機能するのかという問いに対して、統計的かつ経済学的な根拠に基づいた説明を可能にする。これは、偶然の産物である「ブラックボックス」から、説明可能で再現性の高い「ホワイトボックス」への移行を意味する。
この科学的かつ体系的なアプローチこそが、AI MQL合同会社が「価値共創モデル」を通じて、プロップトレーディングファームや専門FinTech企業といった洗練された顧客に提供する中核的な価値である 41。我々の提供価値は、単に納品されるコードの品質にあるのではない。それは、偽発見のリスクを体系的に排除し、持続可能で真のアルファを発見するための知的フレームワークそのものにある。我々の「共生的R&Dモデル」が機能するのも、顧客プロジェクトから得られる知見が、このような厳密なプロセスを経て検証された、統計的偶然ではない普遍的なパターンであるからに他ならない 41。
本稿で展開された議論は、現代の金融市場で競争優位性を確立するために不可欠な、知的探求の深度を示している。我々は、このような高度な技術的・戦略的議論を共に深め、貴社独自の課題解決に繋げるためのパートナーとなることを目指している。ご関心をお持ちの専門家各位には、具体的な協業の可能性を探るための「戦略的スコープ定義セッション」への参加を心より歓迎する 41。
引用文献
- Chapter 11 The Dangers of Backtesting – Advances in Financial Machine Learning [Book], https://www.oreilly.com/library/view/advances-in-financial/9781119482086/c11.xhtml
- KBQI Systematic Investing — Part3: Backtesting | by Prof. Frenzel – Medium, https://prof-frenzel.medium.com/kbqi-systematic-investing-part3-backtesting-6b8de49aa1f2
- Slides Backtesting | PDF | Cross Validation (Statistics) | Sharpe Ratio – Scribd, https://www.scribd.com/document/736234638/Slides-Backtesting
- Marcos Lopez de Prado, https://www.quantresearch.org/Lectures.htm
- Advances in Financial Machine Learning – Marcos Lopez de Prado – Reasonable Deviations, https://reasonabledeviations.com/notes/adv_fin_ml/
- Advances in Financial Machine Learning-Marcos Lopez de Prado (Page 185) – FlipHTML5, https://fliphtml5.com/fzqli/zwcp/Advances_in_Financial_Machine_Learning-Marcos_Lopez_de_Prado/185/
- Chapter 8 Feature Importance – Advances in Financial Machine …, https://www.oreilly.com/library/view/advances-in-financial/9781119482086/c08.xhtml
- Advances in Financial Machine Learning Book Summary by Marcos López de Prado, https://www.shortform.com/summary/advances-in-financial-machine-learning-summary-marcos-lopez-de-prado
- 経済時系列の統計 – 岩波書店, https://www.iwanami.co.jp/moreinfo/tachiyomi/0068480.pdf
- 【時系列分析】定常性と非定常性を株価でイメージしよう – note, https://note.com/noa813/n/n2ca36e175855
- 時系列解析(分析)とは|概要やメリット、モデル、進め方、事例を紹介 – スキルアップAI, https://www.skillupai.com/blog/tech/time-series/
- Regime Changes and Financial Markets – Rady School of …, https://rady.ucsd.edu/_files/faculty-research/timmermann/regime_changes_June_22.pdf
- Classification of Normal and Abnormal Regimes in Financial Markets – MDPI, https://www.mdpi.com/1999-4893/11/12/202
- Detecting Regime Changes in Financial Markets using … – IJFMR, https://www.ijfmr.com/papers/2022/5/857.pdf
- Market Regimes Explained: Build Winning Trading Strategies – LuxAlgo, https://www.luxalgo.com/blog/market-regimes-explained-build-winning-trading-strategies/
- Market regime detection using Statistical and ML based approaches | Devportal, https://developers.lseg.com/en/article-catalog/article/market-regime-detection
- Decoding Market Regimes Machine Learning Insights into US Asset Performance Over The Last 30 Years, https://www.ssga.com/library-content/assets/pdf/global/pc/2025/decoding-market-regimes-with-machine-learning.pdf
- Detecting multivariate market regimes via clustering algorithms – Imperial College London, https://www.imperial.ac.uk/media/imperial-college/faculty-of-natural-sciences/department-of-mathematics/math-finance/212236006—James-Mc-Greevy—MCGREEVY_JAMES_01075416.pdf
- A Hybrid Learning Approach to Detecting Regime Switches in Financial Markets – arXiv, https://arxiv.org/abs/2108.05801
- Market Regime Detection: Why Understanding ML Algorithms Matters | by Amina Kaltayeva, https://medium.com/@amina.kaltayeva/market-regime-detection-why-understanding-ml-algorithms-matters-4eb7e8cac755
- Detecting Regime Change in Finance: A Framework with Hidden Markov Model – IISER Pune, http://dr.iiserpune.ac.in:8080/xmlui/handle/123456789/8887
- Fractionally Differentiated – Mlfin.py, https://mlfinpy.readthedocs.io/en/latest/FractionalDifferentiated.html
- Time-Series Forecasting: Unleashing Long-Term Dependencies with Fractionally Differenced Data – arXiv, https://arxiv.org/pdf/2309.13409
- Data and Feature Engineering for Trading Course by Dr Ernest Chan, https://quantra.quantinsti.com/course/data-and-feature-engineering-for-trading
- Book2-Chapter5-Fractionally Differentiated Features – YouTube, https://www.youtube.com/watch?v=acyAhc7B7mI
- Market Manipulation and Market Microstructure – Cornerstone Research, https://www.cornerstone.com/practices/services/market-manipulation-microstructure/
- Market Microstructure Explained – Why and how markets move – Tradingriot.com, https://tradingriot.com/market-microstructure/
- What is Market Microstructure? – Quantitative Brokers, https://www.quantitativebrokers.com/blog/what-is-market-microstructurenbsp
- Market Microstructure: The Hidden Dynamics Behind Order Execution – Morpher, https://www.morpher.com/blog/market-microstructure
- Market Microstructure: Meaning, Advantages and Disadvantages – Angel One, https://www.angelone.in/smart-money/stock-market-courses/market-microstructure-advantages-and-disadvantages
- How Market Microstructure Impacts Trading – NURP, https://nurp.com/wisdom/market-microstructure-and-its-impact-on-trading/
- Order Flow Phenomena – Bookmap, https://bookmap.com/blog/order-flow-phenomena
- Market Making with Alpha – Order Book Imbalance – HftBacktest, https://hftbacktest.readthedocs.io/en/latest/tutorials/Market%20Making%20with%20Alpha%20-%20Order%20Book%20Imbalance.html
- ORDERFLOW IMBALANCE AND HIGH FREQUENCY TRADING, https://tesi.luiss.it/27169/1/701851_PECCHIARI_MATTEO.pdf
- Understanding Feature Importance in Financial Machine Learning | by Lucas Astorian, https://medium.com/@lucasastorian/understanding-financial-feature-importance-7eeb49c2df0b
- Advances in Financial Machine Learning-Marcos Lopez de Prado (Page 144) – FlipHTML5, https://fliphtml5.com/fzqli/zwcp/Advances_in_Financial_Machine_Learning-Marcos_Lopez_de_Prado/144/
- False discovery rate – Wikipedia, https://en.wikipedia.org/wiki/False_discovery_rate
- Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing – Yoav Benjamini; Yosef Hochberg – Purdue Department of Statistics, https://www.stat.purdue.edu/~doerge/BIOINFORM.D/FALL06/Benjamini%20and%20Y%20FDR.pdf
- False Discovery Rate | Columbia University Mailman School of Public Health, https://www.publichealth.columbia.edu/research/population-health-methods/false-discovery-rate
- Online control of the False Discovery Rate in group-sequential platform trials – PMC – NIH, https://pmc.ncbi.nlm.nih.gov/articles/PMC10130539/
- AI MQL