
序論:マイクロ秒がPandLを支配する世界 — 逸失利益の再定義
高頻度トレーディング(HFT)の世界において、競争の次元はもはや人間の認識能力を遥かに超えている。それはナノ秒、マイクロ秒単位で繰り広げられる「光の速さに対する競争」である 1。この極限的な環境では、取引所のコロケーション施設にサーバーを設置し、物理的な距離を数メートル縮めることが死活問題となる 3。通信会社に100万ドルのボーナスを支払い、マンホール内に余分に巻かれた光ファイバーケーブルのたるみを数メートル取り除かせたという逸話は、1マイクロ秒を削るための投資がいかに巨大であるかを物語っている 1。
この熾烈なスピード競争の根底には、「レイテンシーアービトラージ」という極めて具体的な収益機会が存在する 2。これは、異なる取引所間の微小な価格差や、市場情報が更新される瞬間の「古い」気配値を、誰よりも速く捉えて利益を確定させる戦略である。この競争の勝敗は、トレーダーの洞察力ではなく、純粋にシステムの速度によって決まる。ロンドン証券取引所におけるFTSE100構成銘柄の取引を分析したある研究によれば、この種のレイテンシーアービトラージ競争は1分間に約1回の頻度で発生し、その勝敗が決するまでの時間はわずか5から10マイクロ秒(1マイクロ秒は100万分の1秒)である 2。驚くべきことに、この超高速取引が取引量全体の約20%を占めている 2。
この事実から導き出される結論は、HFTにおける「信頼性」の概念を根本的に見直す必要があるということである。従来のIT運用における「ダウンタイム」、すなわちシステムが完全に停止している状態は、もちろん壊滅的な損失をもたらす。しかし、HFTの世界では、システムが100%「稼働」していても、レイテンシーが競合より50マイクロ秒遅いだけで、そのシステムは経済的に全く価値を失う可能性がある。1マイクロ秒の遅延が年間数百万ドルの機会損失に繋がるという試算も存在する 1。平均的なアービトラージ競争の勝利価値は約£2と小さいが、これが1日に何百回と繰り返されることで、微小な遅延は莫大な損失となって積み重なっていく 4。
したがって、システムの性能劣化は、時折発生する断続的な障害ではなく、全ての取引に対して課される「恒常的な機会損失税」として捉えるべきである。レイテンシーやその揺らぎ(ジッター)は、気づかぬうちにアルファを削り取り続ける。さらに、2010年の「フラッシュ・クラッシュ」が示したように、個社のシステムの不安定性は、市場全体のボラティリティを連鎖的に増幅させ、システミックリスクへと発展する可能性すら内包している 1。本稿では、このHFT特有の経済的現実を踏まえ、サイト信頼性エンジニアリング(SRE)が単なる技術的な安定化策に留まらず、いかにしてこの「機会損失税」を最小化し、具体的な投資収益率(ROI)として定量化できるのかを論証する。
第1章:SRE – IT運用から経営規律への進化
サイト信頼性エンジニアリング(SRE)は、ソフトウェアエンジニアリングの原則と手法をITインフラの管理と運用に応用し、特にスケーラブルなシステムの信頼性を自動化によって維持するためのプラクティスとして定義される 7。しかし、その本質的な価値は、技術的な洗練性以上に、HFT企業が抱える根源的な組織課題を解決する経営規律としての側面にこそ存在する。
HFT企業、特にプロップトレーディングファームの内部には、本質的な対立構造が存在する。ビジネスサイド、すなわちトレーダーやクオンツは、市場におけるアルファ(超過収益)が常に減衰していくという現実に直面している。彼らの至上命題は、新たな取引戦略を可能な限り迅速に市場へ投入し、競合に先んじて収益機会を捉えることである。これは、変化の速度を最大化することへの強いインセンティブを生む 8。
一方、インフラサイドのエンジニアは、システムの絶対的な安定性を追求する。彼らが管理するシステムの上では莫大な資金が動いており、わずかなバグや設定ミスが瞬時に巨額の損失を引き起こす可能性がある。そのため、彼らはシステムへの変更に対して本能的に慎重になり、安定性を最優先する。この両者の目標の違いは、必然的に行動の対立を生み出す。「もっと速く新機能をリリースしろ」と要求するビジネスサイドと、「安定性を損なうリスクがある」と抵抗するインフラサイドの緊張関係は、多くの金融機関にとって日常的な光景である 9。
この対立は、どちらかの部署の機能不全を示すものではなく、それぞれの役割に忠実であることから生じる、構造的かつ不可避なものである。問題は、この対立を解決するための共通言語や客観的な判断基準が存在しないことにある。多くの場合、意思決定は声の大きい人物の意見や、部署間の力関係、あるいは主観的なリスク評価によって左右され、非効率的かつ危険な結果を招きかねない。
SREは、この根深い対立を解消するための、データ駆動型のフレームワークを提供する。SREは、開発チームと運用チームの協業を促進する文化とツールセットを導入することで 7、主観的な意見の衝突を、客観的なデータに基づいたリスクとリターンの議論へと昇華させる。例えば、「このリリースは危険だ」というエンジニアの感覚的な懸念は、「このリリースを実行すると、我々が許容できるエラーの予算を$X$%超過する可能性があり、それは過去のデータから$Y$ドルの期待損失に相当する」という定量的な分析に置き換えられる。これにより、ビジネスサイドとインフラサイドは、感情的な対立から脱却し、共通の目標(信頼性を維持しつつイノベーションを最大化する)に向かって協力することが可能になる。これは、AI MQL合同会社が事業戦略として掲げる「プロフェッショナルなシステム管理における譲れない要素」というSREの位置づけと完全に一致するものである 8。SREは単なるシステム管理手法ではなく、高速で変化し続ける市場環境に適応するための、合理的な意思決定を可能にする経営規律なのである。
第2章:SLOとエラーバジェット – 技術目標をP&L管理ツールへ翻訳する
SREが提供するフレームワークの中核をなすのが、サービスレベル目標(SLO)とエラーバジェットという二つの概念である。これらは一見すると技術的な目標設定ツールに見えるが、その真価は、HFTビジネスにおける「リスク許容度」と「投資判断」を定量化するための金融ツールとして機能する点にある。本章では、この抽象的な技術概念を、具体的な損益(P&L)管理の言葉へと翻訳する。
まず、三つの基本要素を定義する。
- SLI(Service Level Indicator – サービスレベル指標): ユーザー体験の質を直接的に示す、定量的な測定値である。HFTシステムにおいては、「注文執行までのレイテンシー」「気配値更新のジッター(遅延の揺らぎ)」「取引APIのエラーレート」などがこれにあたる。これはシステムの「体温」や「血圧」のような生データである 7。
- SLO(Service Level Objective – サービスレベル目標): SLIに基づいて設定される、具体的な目標値である。例えば、「取引リクエストの99.99%を500マイクロ秒以内に処理する」や「システムの可用性を月間99.95%に維持する」といった形で定義される 9。これは単なる技術目標ではない。これは、ビジネスが顧客(この場合はトレーディング戦略そのもの)に対して約束する「信頼性の最低保証レベル」であり、このレベルを維持する限りにおいて事業は健全である、という一種の契約と見なすことができる。
- エラーバジェット(Error Budget): SLOから自動的に導出される、「許容可能な失敗の量」または「信頼性の損失許容量」である 9。例えば、月間の可用性SLOが99.95%であれば、残りの0.05%がエラーバジェットとなる。これは時間に換算すると、約21.6分に相当する 10。この21.6分間は、システムがSLOを下回っても「契約違反」とは見なされない。
ここからが本稿の核心的な主張である。エラーバジェットは、HFT企業のP&Lを管理するための、極めて強力なツールである。
エラーバジェットが残っている状態は、システムがSLOで定めた契約の範囲内で安定しており、ビジネスが計算されたリスクを取りながら新しい戦略(イノベーション)を市場に投入するための「予算」が残っていることを意味する 9。エラーバジェットを消費すること自体は、必ずしも悪いことではない。むしろ、それはビジネスが積極的にリスクを取り、新たなアルファを追求している健全な証拠とさえ言える。
しかし、エラーバジェットが枯渇した、あるいは枯渇しそうな状況は全く意味が異なる。それは、ビジネスが許容できるリスクの「予算」を使い果たしたことを意味する 9。この状態で新たな機能リリースやシステム変更を行うことは、SLOという「顧客との契約」を意図的に破る行為に等しい。それは、もはや計算されたリスクではなく、予測不能な損失を生む可能性のある「補償されないリスク」を抱え込むことを意味する。
したがって、SREの規律では、エラーバジェットが枯渇した場合、開発チームは全ての新機能開発を即座に停止し、利用可能なリソースを全てシステムの信頼性向上に振り向ける、という明確なルールを適用する 9。これは開発チームに対する懲罰ではない。これは、事業全体のP&Lを未知のリスクから守るための、極めて合理的かつデータに基づいた経営判断なのである。
このメカニズムは、前章で述べたトレーダーとエンジニアの対立をエレガントに解決する、自己調整型の経済システムを構築する。開発チームが速度を優先し、不安定なコードをリリースすれば、エラーバジェットは急速に消費され、自動的にリリースが凍結される。これにより、彼らは安定性の向上に注力せざるを得なくなる。逆に、エンジニアが過度に慎重になり、変更をためらえば、エラーバジェットは常に満杯のままである。これは、ビジネスに対して「まだリスクを取る余地がありますよ」という明確なシグナルを送ることになる。
このように、エラーバジェットは、イノベーションの速度とシステムの安定性という二律背反の課題を、単一の指標に統合する。経営層は、主観的な議論に介入することなく、エラーバジェットの状態を監視するだけで、組織が最適なリスク・リターン・バランスを維持しているかを客観的に把握できる。SREは、技術的な問題を、データに基づいた経済的な意思決定へと転換させるのである。
第3章:信頼性のROI算出フレームワーク – 損失回避と機会創出の定量化
SREへの投資が単なるコストではなく、収益に貢献する活動であることを証明するためには、その経済的リターンを具体的に算出するフレームワークが不可欠である。ここでは、HFTの特殊性を考慮した、実践的なROI算出モデルを提示する。
基本的なROIの計算式は ROI = (純利益 / 投資コスト) × 100 で表される 13。この式の各要素を、HFT環境におけるSREの文脈で具体的に定義していく。
3.1. 投資(I)の定義:SREコストの構成要素
SRE導入に伴う投資は、主に以下の要素で構成される。
- 直接コスト: MQL AI合同会社とのSRE保守契約費用や、社内に専任のSREエンジニアを雇用する場合の人件費。
- ツール・インフラコスト: システムの健全性をリアルタイムで把握するための高度な監視・オブザーバビリティツール(メトリクス、ログ、トレースを収集・分析するプラットフォーム)のライセンス費用 7。また、信頼性向上のために必要となるハードウェアの増強やネットワーク機器の刷新といったインフラ改善費用も含まれる。
- 初期投資: SREプラクティスを組織に導入する初期段階で発生する、チームへのトレーニング費用、外部コンサルティング費用、そしてSLO策定やエラーバジェットポリシー構築といったフレームワーク設計にかかる時間的コスト 16。
3.2. リターン(R)の算出:損失回避額と機会創出価値のモデリング
SREがもたらすリターンは、「損失回避」という受動的な側面と、「機会創出」という能動的な側面の両面から評価する必要がある。
モデル1:壊滅的ダウンタイムによる直接的損失の回避 (Avoided Catastrophic Loss)
これは最も伝統的で分かりやすいリターンの要素である。システムが完全に停止した場合の損失額を計算する。
- 逸失利益: 計算式の基本は 損失額 = (平均時間あたり収益) × (停止時間) となる 17。
- 二次的コスト: これに加え、インシデント対応にあたるITスタッフの残業代や緊急で依頼する外部コンサルタント費用といった直接的な復旧コスト 18、システム停止中に業務が滞るトレーダーやクオンツの生産性損失 18、さらにはSLA(サービスレベル契約)違反による取引先への違約金や、規制当局から課される罰金といった間接的なコストも考慮に入れる必要がある。
モデル2:性能劣化による恒常的損失の回避 (Avoided Performance Degradation Loss)
本稿において最も重要なリターン要素であり、HFTにおけるSREの真価が問われる部分である。 システムが完全に停止せずとも、わずかな性能劣化が継続的に生み出す「機会損失税」をどれだけ削減できるかを定量化する。
- メカニズム: HFT市場では、注文は価格優先・時間優先の原則で約定される。レイテンシーがわずかに増加するだけで、自社の注文がキューの後方に置かれ、約定の優先順位が低下する。これにより、有利な価格での約定機会を逃したり(機会損失)、不利な価格で約定せざるを得なくなったり(スリッページ増大)する 20。
- 定量化モデル: 学術的な研究で用いられる複雑な数理モデル 20 を参考にしつつ、実務で適用可能な簡易的アプローチを以下に提案する。
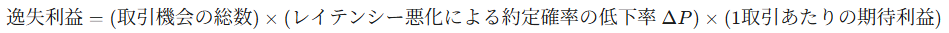
ここで、キーとなる変数 Delta Pは、過去の取引ログデータやバックテスト環境でのシミュレーションを通じて、レイテンシーと約定率の相関関係を統計的にモデル化することで推定する。SREによるインフラ最適化や性能改善が、この $\Delta P$ をどれだけ改善(低下を抑制)できるかが、このモデルにおけるリターンとなる。
モデル3:エラーバジェット活用によるイノベーション速度の最適化 (Value of Innovation Velocity)
これは、SREがもたらす能動的な価値、すなわちビジネスの成長をどれだけ加速させるかを測るモデルである。
- メカニズム: 第2章で論じたように、健全に管理されたエラーバジェットは、開発チームが「どこまでなら安全にリスクを取れるか」という明確な指標を与える。これにより、変更に対する不必要な恐怖心がなくなり、開発チームは自信を持って、より迅速に新しい取引戦略を市場に投入できるようになる。
- 定量化モデル: この「市場投入までの時間短縮(Time-to-Market)」がもたらす先行者利益を金銭価値に換算する。
$$\text{機会創出価値} = (\text{新戦略による期待アルファ}) \times (\text{SRE導入による市場投入の早期化期間}) – (\text{開発コスト})$$
これは、競合他社に先んじて市場の非効率性を利用できる期間がどれだけ増えるかを評価するアプローチである。SREが開発サイクルを1ヶ月早めることができれば、その1ヶ月分の期待アルファがSREの生み出した価値となる。
3.3. ROIの統合的評価と定性的価値
最終的なROIは、上記3つのモデルで算出されたリターンを合算し、投資額で割ることで求められる。
表1:HFTシステムにおけるSRE ROI算出マトリクス
| 構成要素 | カテゴリ | 具体的な指標例 | 定量化アプローチの例 |
| 投資 (I) | 直接コスト | SRE契約費用、エンジニア人件費 | 月額・年額コストの合計 |
| ツール・インフラ | 監視ツールライセンス、インフラ改善費 | 年間ライセンス料、プロジェクト費用 | |
| リターン (R) | 損失回避 | ||
| └ ダウンタイム | システム停止による逸失利益 | $(平均時間あたり利益) \times (SRE導入による想定停止削減時間)$ | |
| └ 性能劣化 | レイテンシー悪化による約定率低下・スリッページ増大の損失 | $(レイテンシー感応度モデル) \times (取引量) \times (SREによる性能改善幅)$ | |
| └ 運用コスト | インシデント手動対応コスト、復旧作業コスト | $(平均対応時間 \times 人件費) \times (SREによるインシデント削減数)$ | |
| 機会創出 | |||
| └ イノベーション速度 | エラーバジェット内での迅速な戦略投入による先行者利益 | $(新戦略の期待利益) \times (市場投入までの時間短縮効果)$ | |
| 定性的価値 | レピュテーションリスク、規制コンプライアンス、人材獲得・維持 | シナリオ分析による潜在的損失額の見積もり、業界ベンチマークとの比較 |
これらに加え、厳密な定量化は難しいものの、ビジネスに重大な影響を与える定性的な価値も存在する。システムの安定性は、顧客や取引カウンターパーティからの信頼を維持し、レピュテーションリスクを低減する 18。また、金融規制当局が求める厳格なシステム管理基準やコンプライアンス要件を満たす上でも不可欠である。そして何よりも、優秀なクオンツ、トレーダー、エンジニアは、不安定で予測不可能な開発・運用環境を嫌う。信頼性の高いプラットフォームは、業界最高峰の人材を惹きつけ、組織に維持するための強力な武器となるのである 23。
結論:SREはコストセンターではなく、プロフィットセンターである
本稿を通じて展開した議論は、HFTの世界における信頼性の役割を再定義するものである。この領域において、信頼性は単なる守りの概念、すなわち障害を防ぐためのコストとして捉えるべきではない。むしろ、それは積極的にアルファを追求するための攻撃の「土台」そのものである。システムの安定性と予測可能性は、計算されたリスクを取り、新たな収益機会を追求するための必須条件なのである。
SREが提供する「盾」は、単に障害という不測の事態からシステムを守るだけではない 8。それは、エラーバジェットという共通の金融言語を通じて、データに基づいた合理的なリスクテイクを組織的に可能にし、ビジネスの俊敏性を最大化する。この強固な「盾」があって初めて、企業はカスタムビルドされた高価な「矛」、すなわち最先端のAI/ML取引戦略の価値を最大限に引き出し、安心して市場に投入することができるのである 8。
したがって、SREへの投資は、火災保険料のような単なるコストとして費用計上されるべきではない。それは、収益を生み出すためのエンジンそのものに対する、戦略的な投資として評価されるべきである。SREはコストセンターではなく、プロフィットセンター、あるいは少なくともプロフィット・イネーブラー(収益実現の促進役)として、その貢献度を測る必要がある。
MQL AI合同会社は、このような「信頼性の経済学」に対する深い洞察と、それを実践に移すための技術力を兼ね備えた戦略的パートナーである。我々は単にコードを書くのではない。我々は、顧客のP&Lに直接貢献するビジネス価値を「共創」するのである 8。
引用
- ヘッジファンドのHFT・HST(高頻度・高速取引)の全貌:超高速取引の世界https://hedgefund-direct.co.jp/column/hedgefund/%E3%83%98%E3%83%83%E3%82%B8%E3%83%95%E3%82%A1%E3%83%B3%E3%83%89%E3%81%AEhft%E3%83%BBhst%EF%BC%88%E9%AB%98%E9%A0%BB%E5%BA%A6%E3%83%BB%E9%AB%98%E9%80%9F%E5%8F%96%E5%BC%95%EF%BC%89%E3%81%AE%E5%85%A8/
- QUANTIFYING THE HIGH-FREQUENCY TRADING “ARMS RACE” | Eric Budishhttps://ericbudish.org/wp-content/uploads/2022/02/Quantifying-the-High-Frequency-Trading-Arms-Race.pdf
- The Microsecond War: How High-Frequency Trading Dominates Major Data Releases | by Cadogan Clutterbuck | Mediumhttps://medium.com/@CadoganClutterbuck/the-microsecond-war-how-high-frequency-trading-dominates-major-data-releases-7b7dbadb7ef7
- How to Calculate How Much High-Frequency Trading Costs Investors – Chicago Boothhttps://www.chicagobooth.edu/review/how-calculate-how-much-high-frequency-trading-costs-investors
- BIS Working Papers – No 955 – Quantifying the high-frequency trading “arms race” – Bank for International Settlementshttps://www.bis.org/publ/work955.pdf
- The Milliseconds Market: The Money-Making on High-Frequency Trading | Fondexxhttps://fondexx.pro/blog/milliseconds-market-money-making-high-frequency-trading
- What is Site Reliability Engineering? – SRE Explained – AWS – Updated 2025https://aws.amazon.com/what-is/sre/
- AI MQL
- SREについて学ぶ – エラーバジェット編 #Google – Qiitahttps://qiita.com/katsulang/items/feb3070666607b7c924c
- SLI、SLO、エラーバジェット導入の前に知っておきたいこと | sreake.com | 株式会社スリーシェイクhttps://sreake.com/blog/sli-slo-good-practices/
- SREの主要な原則 – エラーバジェット -|初歩からのSRE概念入門 – Zennhttps://zenn.dev/persona/books/7820d83da01b4f/viewer/e00e28
- 円滑なエラーバジェット運用に向けた取り組み – Visional Engineering Bloghttps://engineering.visional.inc/blog/302/error-budget/
- ROASとは?計算方法やROI・CPAとの違いをわかりやすく解説 – Salesforcehttps://www.salesforce.com/jp/blog/jp-roas-explained-in-simple-terms/
- ROI(投資対効果)とは?計算方法・重要性・目安・改善策・ROASとの違いまで解説 | Salesforcehttps://www.salesforce.com/jp/marketing/lead-generation-guide/what-is-roi/
- Return on Investment Tool – AHRQhttps://www.ahrq.gov/sites/default/files/wysiwyg/professionals/systems/hospital/qitoolkit/combined/f1_combo_returnoninvestment.pdf
- How to Calculate Test Automation ROI | BrowserStackhttps://www.browserstack.com/guide/calculate-test-automation-roi
- How to Calculate Downtime and Its Associated Costs – Perfsolhttps://perfsol.tech/calculating-downtime
- Calculating Unplanned Downtime Costs Effectively – Steve Stedmanhttps://stevestedman.com/2025/02/calculating-the-true-cost-of-unplanned-downtime/
- How to Calculate Downtime Costs – Understanding the Financial Impact – Peoplegeisthttps://www.peoplegeist.com/en/how-to-calculate-downtime-costs-financial-impact-production
- The Cost of Latency in High-Frequency Trading – Ciamac Moallemihttps://moallemi.com/ciamac/papers/latency-2009.pdf
- Latency Arbitrage Formula for HFT Strategies – QuestDBhttps://questdb.com/glossary/latency-arbitrage-formula-for-hft-strategies/
- OR Forum—The Cost of Latency in High-Frequency Trading – Columbia Business Schoolhttps://business.columbia.edu/sites/default/files-efs/pubfiles/25476/Moallemi_latency.pdf
- How to Calculate the Cost of Downtime – YouTubehttps://www.youtube.com/watch?v=leZbQU_ODLA